Segmentación automática de objetos con Amazon SageMaker Ground Truth
07/01/2020

Amazon SageMaker Ground Truth le ayuda a crear conjuntos de datos de entrenamiento de alta precisión para Machine Learning (ML) rápidamente. Ground Truth ofrece un fácil acceso a terceros y sus propios etiquetadores humanos y les proporciona flujos de trabajo e interfaces integrados para tareas de etiquetado comunes.
Además, Ground Truth puede reducir sus costos de etiquetado hasta en un 70% mediante el etiquetado automático, que funciona mediante la capacitación de Ground Truth a partir de los datos que los humanos han etiquetado para que el servicio aprenda a etiquetar los datos de forma independiente.
La segmentación semántica es una técnica de Machine Learning de visión por ordenador que implica asignar etiquetas de clase a píxeles individuales en una imagen. Por ejemplo, en los cuadros de video capturados por un vehículo en movimiento, las etiquetas de clase pueden incluir vehículos, peatones, carreteras, señales de tránsito, edificios o fondos.
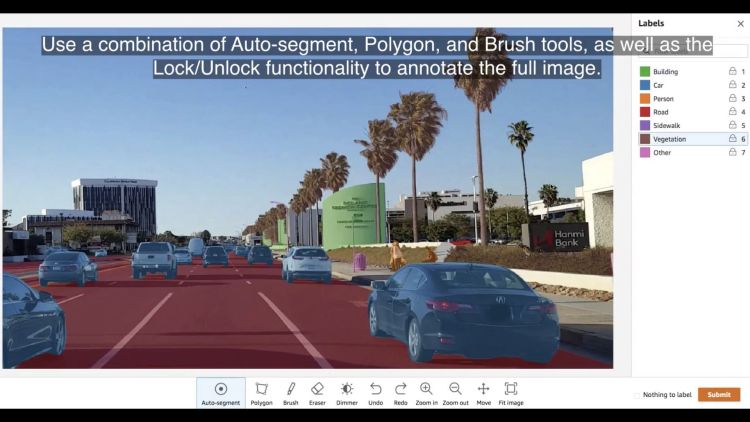
Esto proporciona una comprensión de alta precisión de las ubicaciones de diferentes objetos en la imagen y a menudo se usa para construir sistemas de percepción para vehículos autónomos o robótica.
Para construir un modelo Machine Learning para la segmentación semántica, primero es necesario etiquetar un gran volumen de datos a nivel de píxel. Este proceso de etiquetado es complejo. Requiere etiquetadores calificados y un tiempo considerable: algunas imágenes pueden tardar hasta dos horas en etiquetarse con precisión.
Para aumentar el rendimiento de etiquetado, mejorar la precisión y mitigar la fatiga del etiquetador, Ground Truth agregó la función de segmento automático a la interfaz de usuario de etiquetado de segmentación semántica.
La herramienta de segmento automático simplifica su tarea al etiquetar automáticamente las áreas de interés en una imagen con solo una entrada mínima. Puede aceptar, deshacer o corregir la salida resultante del segmento automático.
Con esta nueva característica, puede trabajar hasta diez veces más rápido en tareas de segmentación semántica. En lugar de dibujar un polígono ajustado o usar la herramienta de pincel para capturar un objeto en una imagen, dibuja cuatro puntos: uno en los puntos superior, inferior, izquierdo y derecho del objeto. Ground Truth toma estos cuatro puntos como entrada y utiliza el algoritmo Deep Extreme Cut (DEXTR) para producir una máscara ajustada alrededor del objeto.
La función de segmento automático automatiza la segmentación de áreas de interés en una imagen con una entrada mínima del etiquetador, y acelera las tareas de etiquetado de segmentación semántica.
Más información: https://amzn.to/2QX3gww
0 comentarios